TETHYS Database Model
The database model used by TETHYS is based on a relational database model. The model includes several tables that store information about different types of research data. The main tables in the database include:
-
Resource Table: This table stores information about the resources that are managed by the system. Each resource is assigned a unique identifier and the table includes fields for the title, author, publication date, and other metadata associated with the resource.
-
User Table: This table stores information about the users of the system. Each user is assigned a unique identifier, and the table includes fields for the user's name, email address, and other contact information.
-
Collection Table: This table stores information about collections of resources. Each collection is assigned a unique identifier and the table includes fields for the title, description, and other metadata associated with the collection.
-
License Table: This table stores information about the licenses that are associated with the resources in the system. Each license is assigned a unique identifier, and the table includes fields for the license type, terms, and other information.
-
File Table: This table stores information about the files that are associated with the resources in the system. Each file is assigned a unique identifier, and the table includes fields for the file name, file type, and other metadata.
The database model used by TETHYS is designed to be flexible and extensible, allowing for the addition of new tables and fields as needed to support different types of digital resources.
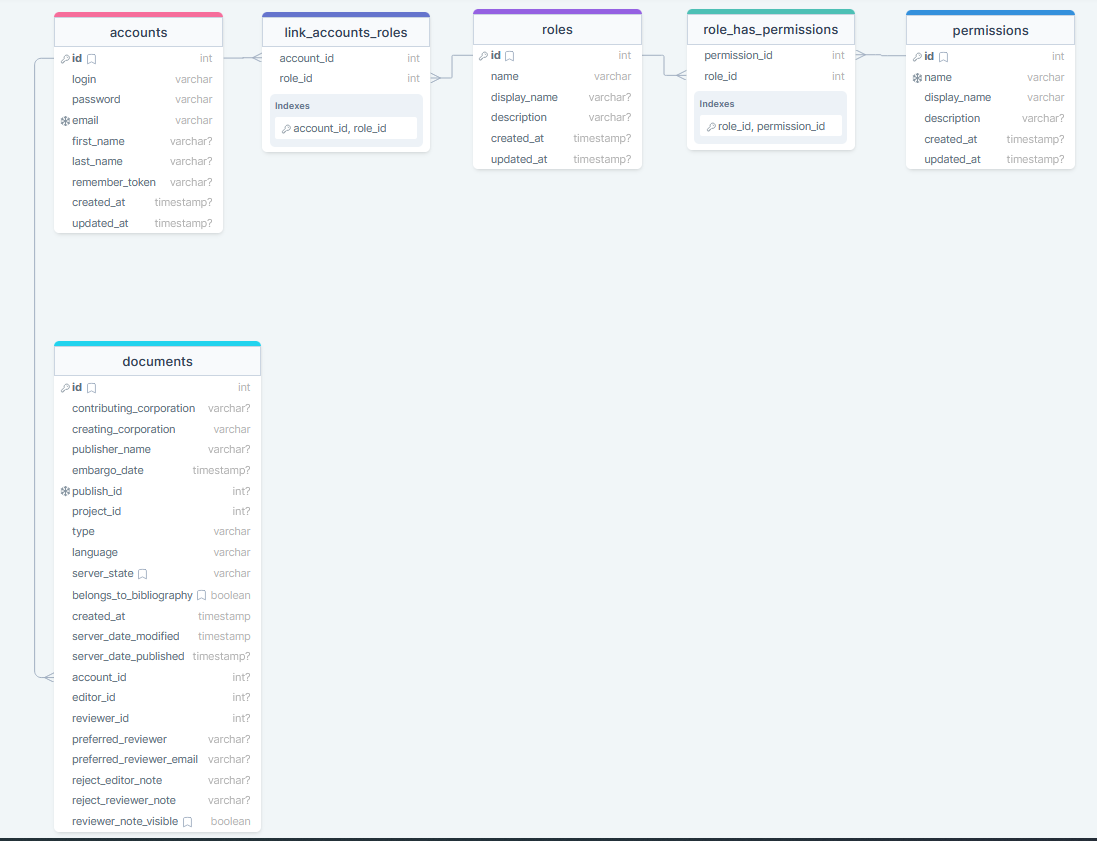
The ACL tables used by TETHYS are:
TETHYS provides an Access Control List (ACL) system that is used to manage users, user roles and permissions.
-
accounts: This table stores information about the users of the system. Each user is assigned a unique identifier, and the table includes fields for the user's name, email address, and timestamps.
-
roles: This table stores information about the roles that are available in your application. Each role has a unique identifier and a name that describes the role. TETHYS is using the following rules:
- admin role: for editing user accounts, roles and permissions
- submitter role: Submitters submit original research datasets. Submitters are responsible for ensuring that their submissions meet the repository's guidelines and standards.
- editor role: TETHYS editors are responsible for overseeing the content and quality of the research repository. They review submissions to ensure they meet the repository's standards and may provide feedback to submitters. They may also work with reviewers to ensure that submissions are evaluated fairly.
- reviewer role: Reviewers are responsible for evaluating submissions to the research repository. They may be assigned specific submissions to review, and they provide feedback on the quality and relevance of the research. Reviewers typically have expertise in the field related to the research and may be asked to provide a written report or score to help the editor make a decision about whether to accept or reject the submission.
-
permissions: This table stores information about the permissions that are available for the roles. Each permission has a unique identifier, a name that describes the permission, and a short code that represents the permission.
-
role_has_permissions: This table stores the relationship between roles and permissions. Each row in this table represents a role that has been granted a specific permission.
-
link_account_roles: This table stores the relationship between users (Accounts) and roles. Each row in this table represents a user that has been assigned a specific role.
-
documents: This table stores information about the datasets that are managed by the system. Each dataset is assigned a unique identifier (publish_id) and the table includes fields for the embargo date, publication date, creation date update date and other metadata associated with the resource. Information to titles, authors, contributors, files and file checksums are stored in extra related tables (see next chapter related tables).
Dataset tables for filtering:
Many research repositories allow you to filter content based on specific criteria. For example, you may be able to filter by publication date, author, contributor, title, abstract, keyword or spatially via coverage. This can be helpful if you are looking for a specific type of resource or trying to narrow down your search results. TETHYS also organizes content into collections based on specific themes or topics. Collections can be a great way to quickly find relevant resources and may be curated by experts in the field.

-
datset_abstracts: This table stores all the descriptions to an uploaded dataset. Allowed values for an abstract type are: 'Abstract', 'Methods', 'Series_information', 'Technical_info', 'Translated' and 'Other'. For ech abstract you have to select the language.
-
datset_titles: This table stores all the titles to an uploaded dataset. Allowed values for a title type are: 'Main', 'Sub', 'Alternative', 'Translated' and 'Other'. For ech title you have to select the language.
-
dataset_subjects with pivot table link_dataset_subjects: This table stores all the keywords. Until now only uncontrolled keywords are possible (attribute type is default 'uncontrolled'). The attribute 'external_key' you will need for refencing controlled subjects.
-
datset_abstracts: This table stores all the descriptions to an uploaded dataset. Allowed values for an abstract type are: 'Abstract', 'Methods', 'Series_information', 'Technical_info', 'Translated' and 'Other'.
-
persons: All dataset authors and contributors are stored inside this table. The table includes fields for the user's name, email address, and other contact information.
In the pivot table there are attributes for:- sort_order: sorting the authors and contributors
- allow_email_contact: if the email contact is allowed
- contributor_type: 'ContactPerson', 'DataCollector', 'DataCurator', 'DataManager', 'Distributor', 'Editor', 'HostingInstitution', 'Producer', 'ProjectLeader', 'ProjectManager', ProjectMember', 'RegistrationAgency', 'RegistrationAuthority', 'RelatedPerson', 'Researcher', 'ResearchGroup', 'RightsHolder', 'Sponsor', 'Supervisor', 'WorkPackageLeader' and 'Other'
-
coverage: The spatial search functionality in Tethys allows users to find and access geospatial data that are relevant to their research or analysis by specifying a geographic extent that matches their area of interest. The 'x_min' and 'x_max' values represent the minimum and maximum x-coordinates (usually longitude) of the bounding box, while 'y_min' and 'y_max' represent the minimum and maximum y-coordinates (usually latitude). By specifying these coordinates, users can filter datasets based on their geographic location, making it easier to find relevant data for their analysis. Additionaly there are attributes for the elevation, depth and time coverage.
-
projects: When a user uploads data to TETHYS, they can assign them to one project. These projects could represent research studies, experiments, collaborations, or any other relevant grouping of data. Once the data have been assigned to a project, users can then filter the datasets in TETHYS based on the project they are associated with.
-
collections: ...
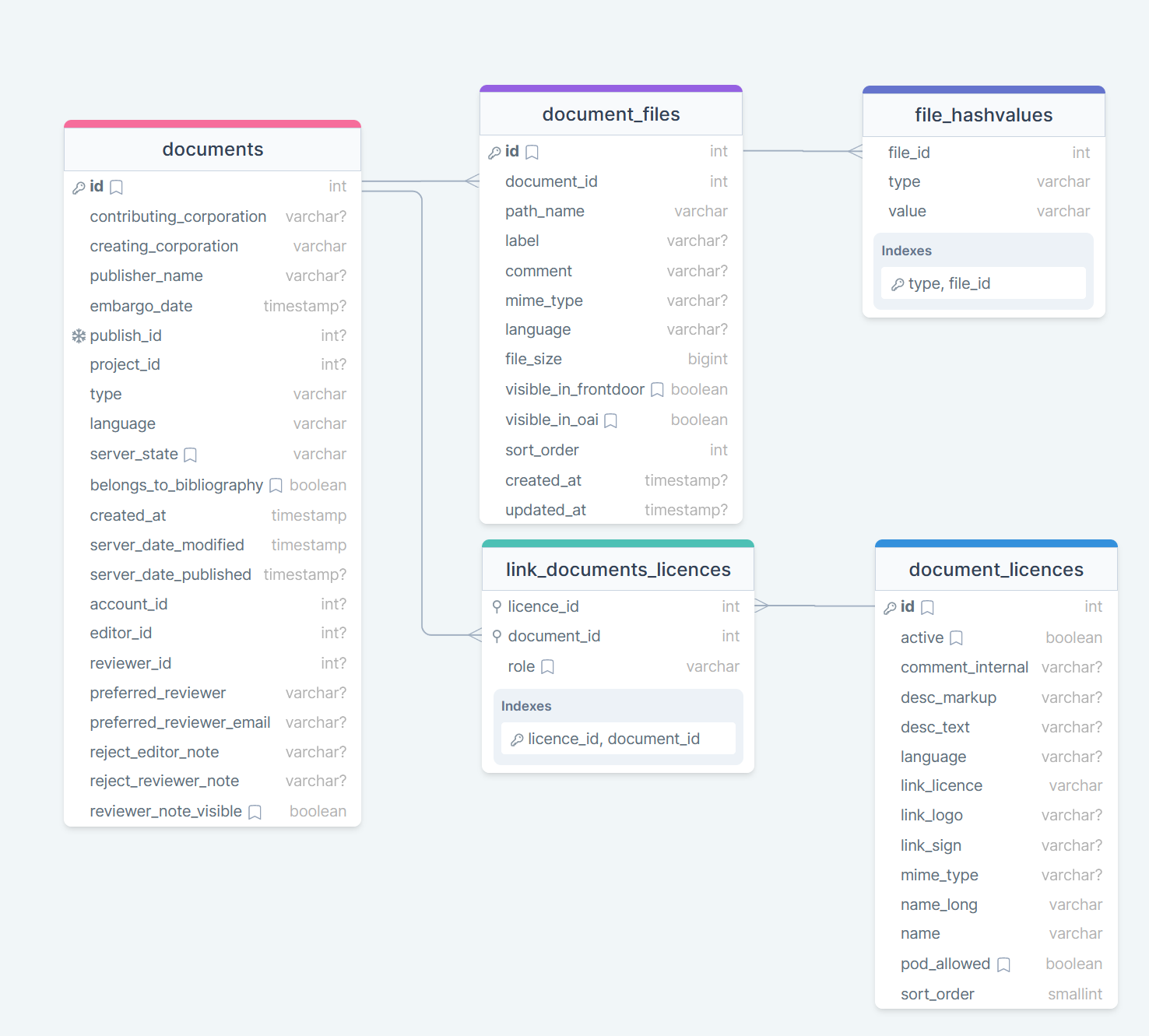
Tables for file metadata and file checksums:
TETHYS stores metadata about all files in a separate database table ('document_files').
-
document_files: TETHY stores the following metadata attributes for every uploaded file:
- path_name: path to the file on the harddisk
- label: name of the file presented aon the web frontend
- comment: optional comments to files are possible
- mime_type
- file_size in bytes
- visible_frontdoo: is the file visible on the web frontend
- visible_oai: is the file vissible iin the oai response
- sort_order: for the order aof all files associated to a dataset
- timestamp attributes: created_at and update_at
-
file_hashvalues: TETHYS RDR calculates internal checksums during the ingestion workflow. These checksums ensure that ingested data has not been altered or damaged. A checksum is a short sequence of bits or bytes that is calculated from the data using an algorithm. If even a single bit of the data changes, the checksum will also change, indicating that the data has been changed unintentionally on the file store. During the file upload, TETHYS calculates and stores md5 and sha512-checksums for each file (see attribute type).
-
document_licences with pivot table 'link_document_licences': Creative Commons licenses are commonly used to govern the use and distribution of research data. For example, a researcher might choose to make their research data available under a CC-BY license, which allows others to share, adapt, and build upon the data as long as they provide attribution to the original author. All preferred CC licences for TETHYS are described in the manual (manual, p. 15).
Dataset references & identifiers
During the ingestion of the new dataset, there is the possibility to refer to existing publications (table 'document_references') through persistent Identifier (PID). Such identifiers are precisely defined and described in Tethys RDR under the metadata element "Dataset References" as identifier types: DOI, HANDLE, ISBN, URL, and URN. (manual, p. 21).
Self referencing identifiers of a dataset are stored inside the table 'document_identifiers'.
In addition, the relation types (the kind of relationship) are precisely defined (manual, p. 22). In most cases, the relation type “IsNewVersionOf” will be used.
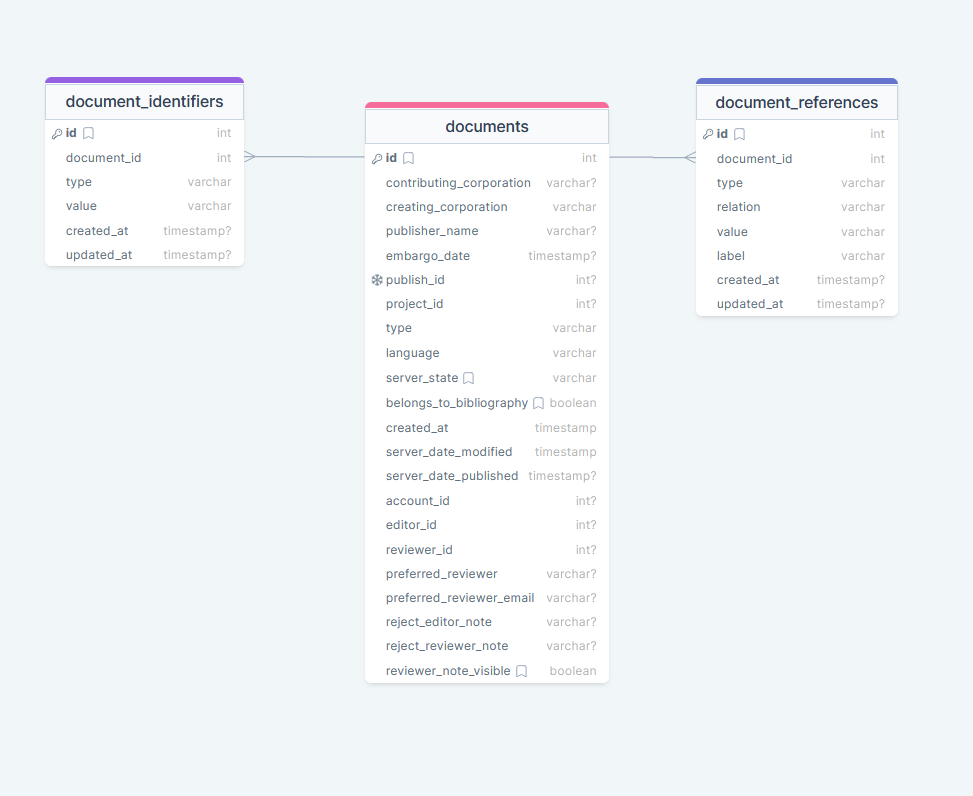
- document_identifiers:
- 'type': allowed values are: 'doi', 'handle', 'isbn', 'issn', 'url' and 'urn'
- 'value': for example der url of a doi
- document_references:
- 'type': allowed values are: 'DOI', 'Handle', 'ISBN', 'ISSN','URL' and 'URN'
- 'value': for example der url of a doi
- 'relation': the following relation types are allowed in TETHYS: 'IsSupplementTo', 'IsSupplementedBy', 'IsContinuedBy', 'Continues', 'IsNewVersionOf', 'IsPartOf', 'HasPart', 'Compiles', 'IsVariantFormOf'
TETHYS lookup tables

-
document_xml_cache: all of the dataset's relations are stored in an internal XML format with a timestamp. Once the internal XML file has been created, it could be parsed and transformed into various output formats, including OAI-PMH (dublin core and datcite protocols used for OAI queries) and DOI registration data. These output formats would likely include information about the dataset itself (such as title, author, abstract, subjects, language, collection and publication date), as well as information about its relationships to other records in the repository. This metadata could then be used by other systems or services to facilitate discovery and access to the published dataset:
- 'xml_data': stores the internal TETHYS xml.
- 'xml_version': if the database model changes, the version of the internal xml must be increased.
- 'server_date_modified': timestamp of dataset publication or doi update date
-
mime_types:
- 'name': this attribute holds the mime-type. e.g. 'text/csv', 'application/x-sqlite3', 'image/jpeg'
- 'file_extension': all allowed file extension for a mime-type: e.g. jpg|jpeg|jpe for the mime-type 'image/jpeg'
- 'enabled': defines if the mime-type is enabled for TETHYS
- timestamp attributes 'cretaed_at' and 'updated_at'
-
languages:
TETHYS Migration Code
Lucid is a powerful and easy-to-use ORM that enables you to work with databases using an object-oriented approach.
With Lucid, you can define models that map to database tables and use these models to query, insert, update, and delete data in the database. The ORM supports a variety of database drivers, including MySQL, PostgreSQL, SQLite, and MSSQL, and provides a consistent API across all of them.
All models for the TETHYS backend can be found here: TETHYS ORM Models